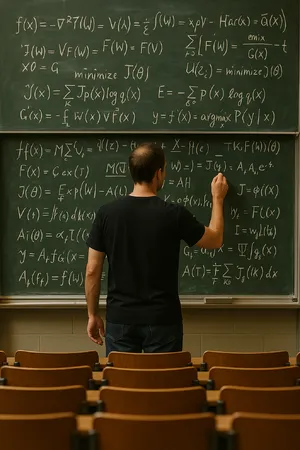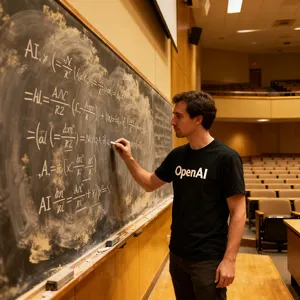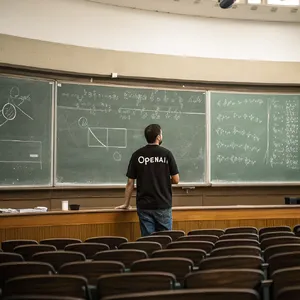Summary for Ultra Hard
The Ultra Hard category proved to be a massive stumbling block for many mainstream AI models! It effectively separated the true powerhouses from those that rely heavily on their baseline training biases.
Key Discoveries:
- 🏆 Top Performers: Nano Banana Pro, GPT Image 1.5, and ChatGPT 4o consistently demonstrated the rare ability to follow complex, multi-layered instructions without defaulting to generic tropes.
- 📉 The Logic Trap: Most models completely failed the inversion test. When asked to generate a horse riding an astronaut, 80% of models defaulted to the standard "astronaut riding a horse" instead.
- 🔡 Text is Still a Killer: Breathtaking visuals from highly artistic models like Midjourney v7 were repeatedly penalized due to hallucinatory, gibberish text in UI panels or on clothing.
- 😲 Surprising Results: Specialized and newer models outpaced the legacy giants. For example, Ideogram 3.0 (Quality) showed absolute mastery over integrating text into environments naturally.
General Analysis & Useful Insights
Navigating the Ultra Hard category requires models to perform an incredibly delicate balancing act between hyper-realism and extreme prompt obedience. Here is a deeper look at the patterns we uncovered:
1. Overcoming Training Bias 🧠
The most prominent failure mode across the entire dataset is "Prompt Override." When presented with an absurd or inverted scenario, models panic and revert to their most comfortable training data. In the Astronaut and Horse test, nearly every model failed. However, Nano Banana Pro and Flux 2 Pro broke the mold, proving they actually understand spatial relationships rather than just matching keywords to concepts.
2. The Gibberish Penalty 📝
Top-tier aesthetic models often snatch defeat from the jaws of victory due to poor text generation. In the OpenAI Chalkboard prompt, models like Midjourney V6.1 generated beautiful lecture halls but ruined the output with unreadable text like "opc Al". Conversely, Ideogram 3.0 (Quality) and Grok Imagine proved highly reliable at embedding crisp, legible typography into natural environments without breaking immersion.
3. Uncanny Valley and Anatomy 🖐️
Photorealism tests revealed that while models can render beautiful lighting and textures, they still deeply struggle with structural anatomy and the dreaded "plastic skin" effect. The ASL Thank You prompt was a graveyard of anatomical horrors! Models generated extra fingers, mutated claws, and wildly incorrect gestures—including an offensive middle finger from Z-Image Turbo. True photorealism requires biological logic, not just high resolution.
Best Model Analysis by Use Case
Different models showed distinct specializations across the challenging scenarios in this category. Here is a breakdown of where to turn based on your specific needs:
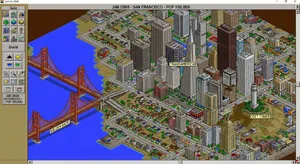
🎮 UI and Retro Game Generation
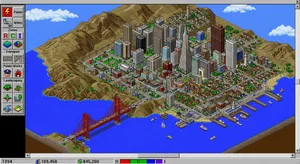
For prompts requiring specific pixel-art aesthetics and UI overlays, like the SimCity 2000 test, ChatGPT 4o and Imagen 4.0 Ultra were absolutely flawless. They captured the exact retro UI borders and tool icons, whereas others generated modern mobile game interfaces or total gibberish.
📝 Text on Objects and Signage
If your use case requires precise typography—such as the cardboard sign in AGI Arrived or the retro screen in Apple II—Grok Imagine, Nano Banana Pro, and Ideogram 3.0 (Quality) are our top recommendations. They handle kerning, perspective, and marker/chalk textures beautifully without misspelling words.
🧠 Complex Spatial Logic & Rule Reversal
For prompts that defy normal physics or standard relationships, Nano Banana Pro is the undeniable winner. Its rendition of the Nano Space Horse correctly solved the logic puzzle by putting the horse in a custom spacesuit on the astronaut's back! This showcases an incredible level of recursive creativity.
🧏 Human Anatomy and Specific Gestures
When you need exact human gestures, standard models usually just guess blindly. For the highly specific ASL Thank You prompt, ChatGPT 4o and Nano Banana Pro were the only models to accurately depict the flat hand starting at the chin. They prove they have a much deeper semantic understanding of specialized human actions than their competitors.