























































































































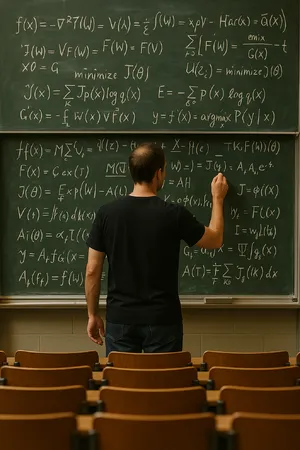
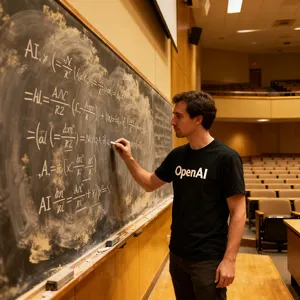

















































































Summary for Ultra Hard
The Ultra Hard category lived up to its name, serving as a brutal stress test for modern AI models. While many models excel at standard photorealism, this dataset revealed significant gaps in logical reasoning and spatial intelligence.
Key Findings
- Logic is the new frontier: The prompt A realistic astronaut being ridden by a horse caused a massive failure rate. Most models ignored the syntax and defaulted to the common trope of a human riding a horse. Only a select few, like Nano Banana Pro and Flux 2 Pro, successfully reversed the roles.
- Text is solving itself: Models like GPT Image 1.5 and Ideogram 3.0 (Quality) are now handling complex text integration (handwriting on cardboard, chalkboards) with near-perfect accuracy.
- Anatomy remains tricky: The ASL 'thank you' gesture stumped almost everyone, with models confusing it for "thinking" poses or the "OK" sign. Nano Banana Pro and ChatGPT 4o were rare successes here.
Top Performers
- 🏆 GPT Image 1.5: Demonstrated the highest consistency across logic, text, and texture.
- 🥈 Nano Banana Pro: Showed surprising ingenuity in interpreting difficult logical prompts.
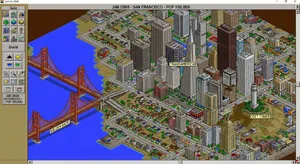
- 🥉 ChatGPT 4o: Excellent at stylistic mimicry (SimCity) and general adherence.