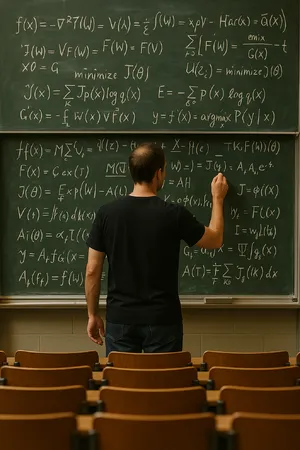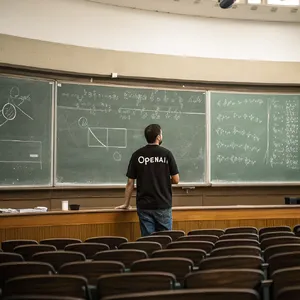Summary for Ultra Hard
The Ultra Hard category lives up to its name, revealing significant gaps between the top-tier models and the rest of the pack. This is where models are truly stress-tested, and the results are telling. Here are the key takeaways:
-
🏆 Top Performers: Google's models were dominant. Imagen 4.0 Ultra stands out as the best overall performer (average score: 7.5), followed closely by Imagen 3.0 (6.7) and Reve Image (Halfmoon) (6.6). These models demonstrated superior prompt adherence and photorealism.
-
🤯 The Great Filters: Three challenges consistently separated the best from the rest:
- Text Generation: Most models failed catastrophically when asked to render specific text, branding, or symbols, producing gibberish. This was the single most common reason for low scores on prompts like AGI has arrived! and OpenAI-branded T-shirt.
- Anatomy & Gestures: The ASL 'thank you' prompt was a near-universal disaster, highlighting that rendering specific, accurate hand gestures is still an unsolved problem. Many models produced malformed hands or incorrect signs.
- Logical Reversals: The prompt for an astronaut being ridden by a horse was failed by every single model. All of them defaulted to the more logical 'astronaut riding a horse,' revealing a deep-seated bias against absurd or reversed concepts.
-
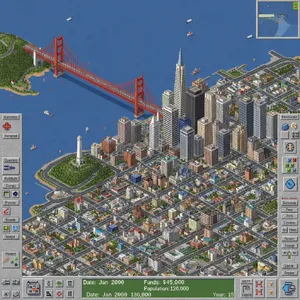
✨ Surprising Successes: The ability of models like ChatGPT 4o and Nano Banana (2.5 Flash) to replicate the highly specific retro aesthetic of SimCity 2000, complete with UI elements, was a standout achievement.
Quick Conclusions
For complex tasks requiring high fidelity, conceptual understanding, and the best chance at readable text, Google's Imagen 4.0 Ultra is the top recommendation. For creative prompts with recursive logic, Reve Image (Halfmoon) showed remarkable aptitude. Users should be extremely cautious when prompting for specific text or hand gestures, as even the best models struggle immensely with these tasks.
General Analysis & Useful Insights
Digging deeper into the Ultra Hard category reveals fascinating patterns in how different AI models approach and fail at complex tasks. Here's a breakdown of the key insights.
Comparative Strengths & Weaknesses
-
Google's Powerhouses (Imagen 4.0 Ultra, Imagen 3.0): These models are the clear leaders in photorealism and literal prompt interpretation. Their ability to generate high-quality, believable images with excellent detail, as seen in the flawless Edge of the Earth and AGI Sign prompts, sets a high benchmark. They also had the best (though still imperfect) performance on text generation.
-
The Conceptual Ace (Reve Image (Halfmoon)): While a strong all-rounder in realism, this model's unique strength is its conceptual understanding. It was one of only two models to correctly interpret the robot painting a self-portrait prompt, producing a perfect 10/10 image that nailed the recursive idea where most others failed.
-
The Stylistic Specialist (ChatGPT 4o): While inconsistent on text and anatomy, this model excels at stylistic replication. Its ability to perfectly capture the retro aesthetic of the SimCity 2000 prompt, including the UI, was a standout success that many other models missed entirely.
-
The Artistic Gambler (Midjourney v7, Midjourney V6.1): Midjourney consistently produces images with high artistic merit and a unique, cinematic feel. However, it often sacrifices prompt adherence for aesthetic effect. Its results for the Singapore hawker were moody and beautiful but missed key details. Its complete misinterpretation of the Robot Painting prompt, showing a human painting a robot, demonstrates its unreliability for tasks requiring strict adherence.
Common Failure Modes 🧐
-
Logical Inversion: The most glaring pattern was the universal failure to depict an astronaut being ridden by a horse. Every model inverted the prompt to show an astronaut riding a horse. This indicates a strong model bias towards more plausible or commonly depicted scenarios, overriding explicit instructions.
-
Gibberish is the Norm: Text is the Achilles' heel of image generation. In the OpenAI shirt prompt, nearly every model produced nonsensical equations. The models that succeeded on the simpler text of the AGI Sign prompt still struggled with more complex branding or symbols.
-
Anatomical Anarchy: The ASL prompt was a minefield. Models either generated a completely different sign (like 'I love you' or 'stop') or produced grotesquely malformed hands. This attempt by DALL-E 3 and this one by Midjourney v7 are prime examples of catastrophic anatomical failure.
Best Model Analysis by Use Case
For the Ultra Hard category, choosing the right model is critical. Your choice should depend entirely on what aspect of the complex prompt you want to prioritize.
🚀 Best for Ultimate Photorealism & Adherence
If your primary need is a hyper-realistic image that follows your instructions to the letter, these are your best bets.
🧠 Best for Complex Concepts & Abstract Ideas
When your prompt involves recursive logic, abstract concepts, or creative interpretation, you need a model that can 'think' beyond keywords.
-
Top Recommendation: Reve Image (Halfmoon)
-
Strong Alternative: Imagen 4.0 Ultra
-
Why? These two models were the only ones to correctly understand the nuanced request in the Robot Painting prompt. Reve's generation of a robot painting its own portrait in Van Gogh's style demonstrates a superior grasp of conceptual relationships that other models missed, which instead had the robot painting a portrait of Van Gogh himself.
🔤 Best for Text, Branding & Symbols
This remains the most challenging use case, with no model being truly reliable. However, some showed more promise than others.
🎮 Best for Stylistic & Retro Replication
For prompts that require mimicking a very specific artistic style, especially a retro or niche one, precision is key.